Pareto-Efficient Retrieval over Intent-Aware Structured Memory for Long-Horizon Agents
A training-free, retrieval-side memory framework that reaches high answer accuracy at an order-of-magnitude smaller context budget — by treating long-horizon memory as a joint retrieval-and-compression problem over a graph.
Long-horizon language agents accumulate conversation history far faster than any fixed context window can hold. The quality of a memory system is governed by two coupled quantities: the accuracy of the answers it supports, and the context cost — the number of tokens packed into the answer model's prompt for every query.
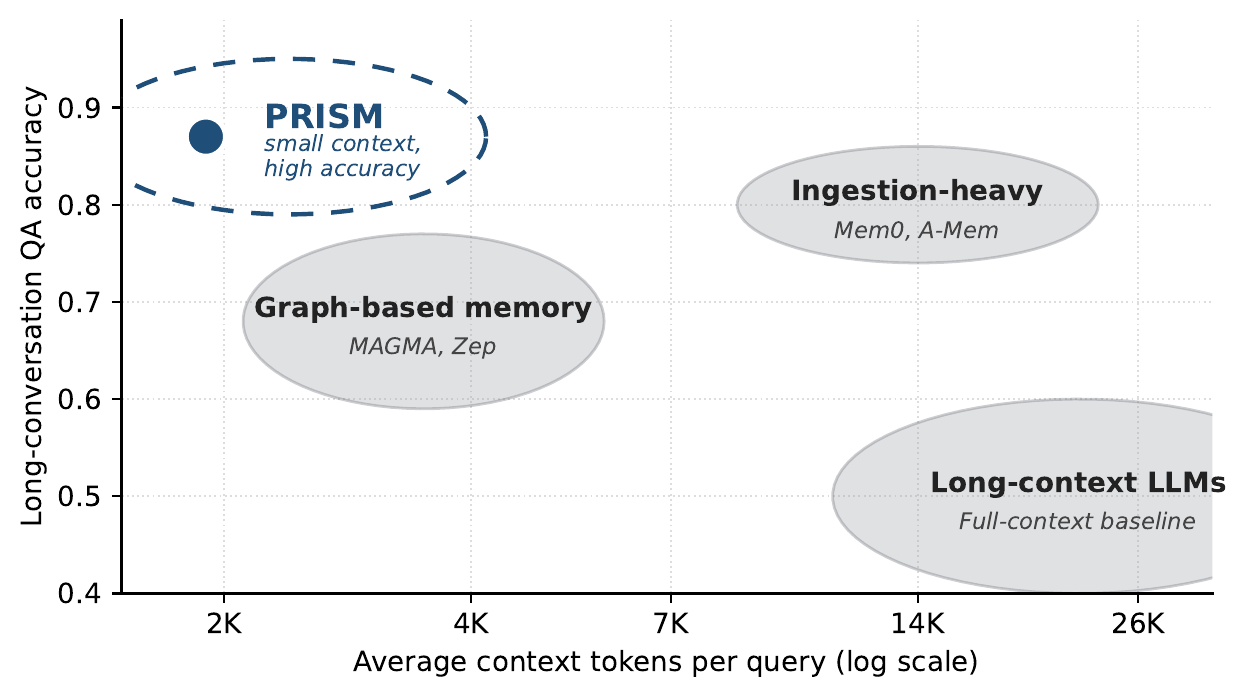
Prior systems advance these along separate axes. Ingestion-heavy systems reach high accuracy but retrieve large candidate pools; long-context backbones pay a heavy token cost for moderate accuracy; graph-based memory adds relational structure but sits at moderate accuracy and cost. The high-accuracy / low-cost corner of the frontier is left largely empty — and PRISM is built to occupy it.
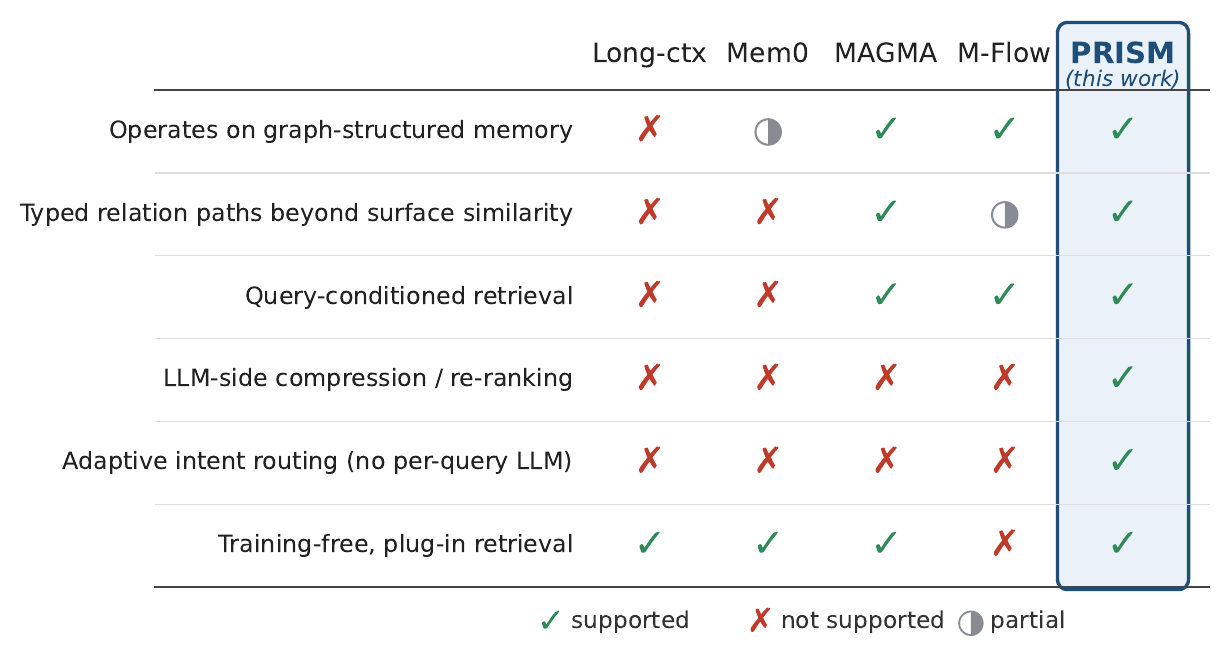
(a) The accuracy–context-cost landscape. Existing memory designs cluster in three regions, leaving the high-accuracy / low-cost corner underfilled. PRISM occupies that corner: small context, high accuracy.(b) Design dimensions. PRISM is the only system that combines all six design dimensions identified as relevant to the long-horizon memory problem.
How It Works
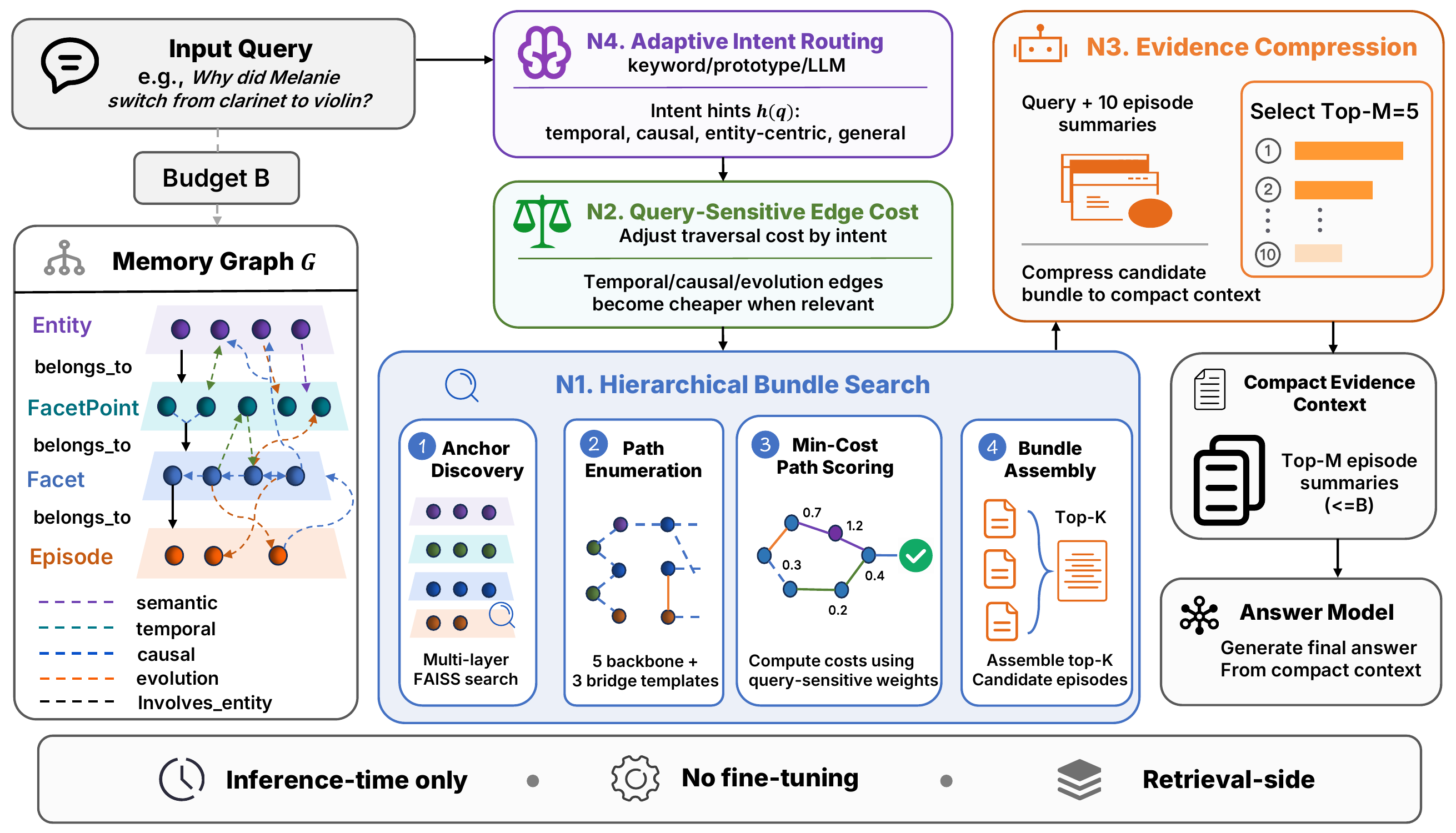
Four orthogonal inference-time modules.
PRISM operates over an existing graph memory — a four-layer hierarchy of Entity → FacetPoint → Facet → Episode connected by typed relation edges. At query time, four modules compose into a fixed sequence. No fine-tuning, no per-query policy, no modification to the upstream ingestion pipeline.
N4
Adaptive Intent Routing
Routes each query through a cheapest-first cascade — keyword → prototype → LLM fallback — so most queries never spend a classifier-side LLM call.
N2
Query-Sensitive Edge Cost
Re-weights traversal cost by detected intent: temporal and causal edges become cheaper exactly when the query needs them.
N1
Hierarchical Bundle Search
Scores each episode by the minimum-cost typed path that reaches it, recovering evidence that flat similarity search misses.
N3
Evidence Compression
A single content-only LLM call re-ranks and compresses the candidate bundle into a compact answer-side context.
Architecture overview. N4 routes query intent; N2 adjusts traversal costs over typed edges; N1 searches relation paths and assembles a candidate bundle; N3 compresses the retrieved evidence into a compact context for the answer model. The pipeline issues at most two LLM calls per query, and only one for the majority handled by N4's cheap tiers.
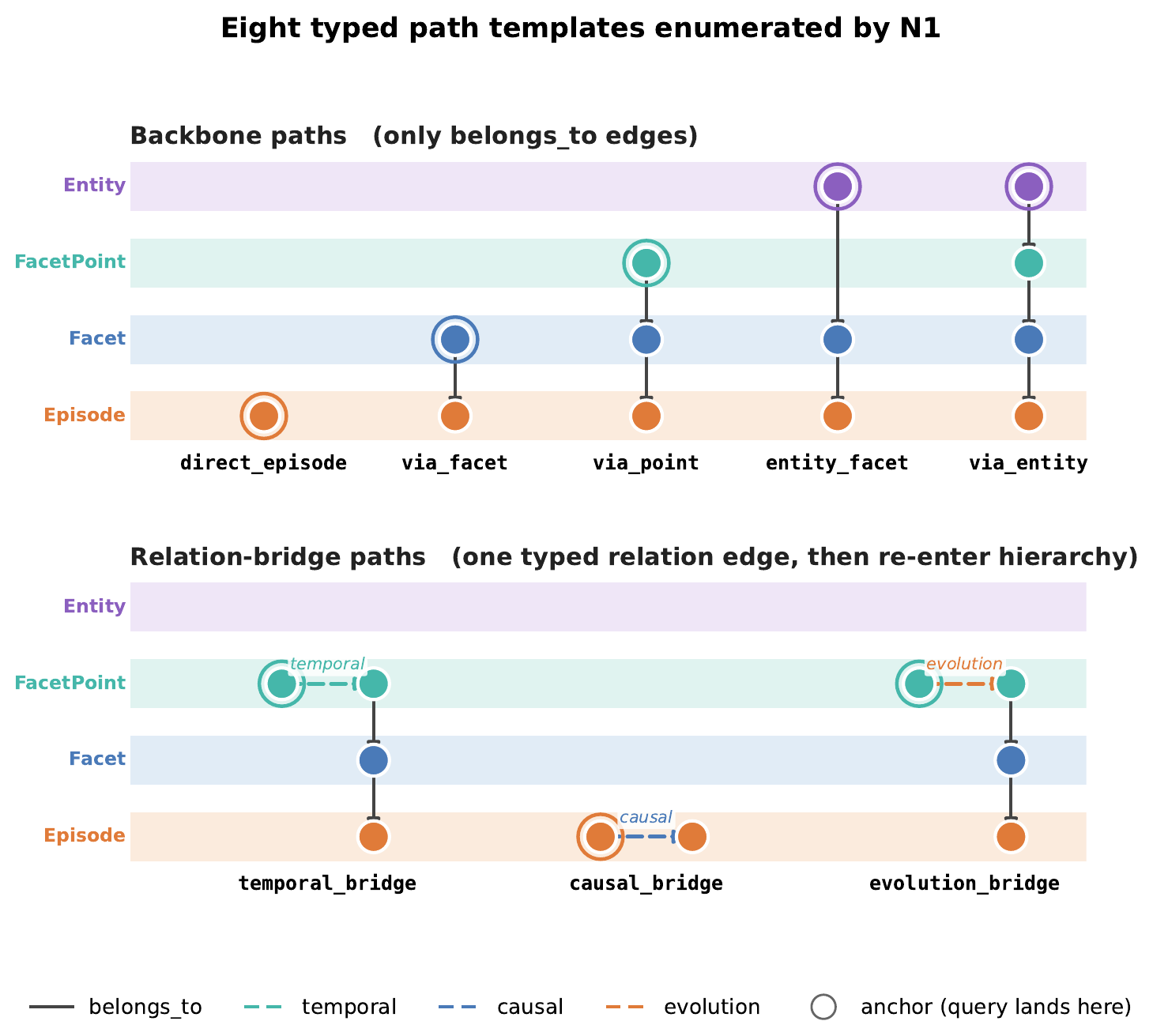
Typed path templates
N1 enumerates eight typed path templates — five backbone paths over belongs_to edges, and three relation-bridge paths that cross one typed relation edge before re-entering the hierarchy. The bridges are the structural basis for answering multi-hop and causal questions.
Eight path templates enumerated by N1. Backbone paths capture evidence established by similarity to the anchor; relation-bridge paths surface indirect evidence whose target shares no surface similarity with the query.
Headline Result
An order-of-magnitude less context, higher accuracy.
0.831
LLM-judge score on LoCoMo (cat 1–4), best of all same-protocol methods
13×
context reduction vs. full-context replay (~26K → ~2K tokens)
+35pp
judge gain over the full-context baseline, at a fraction of the cost
42%
of queries routed through zero-LLM tiers, at no accuracy cost
Experiments
Results on LoCoMo.
Evaluation on the LoCoMo benchmark, categories 1–4 (1,540 QA pairs). All same-protocol rows use gpt-4o-mini as both answer and judge model at temperature 0.0, sharing the same prompts, tokenizer, and token-counting procedure. Per-1K Eff. = judge points per 1K retrieved context tokens.
PRISM wins every same-protocol column and delivers the best accuracy-per-token. Swapping only the answer model to gpt-5.5 lifts the overall score to 0.891 at the same 2,023-token budget.
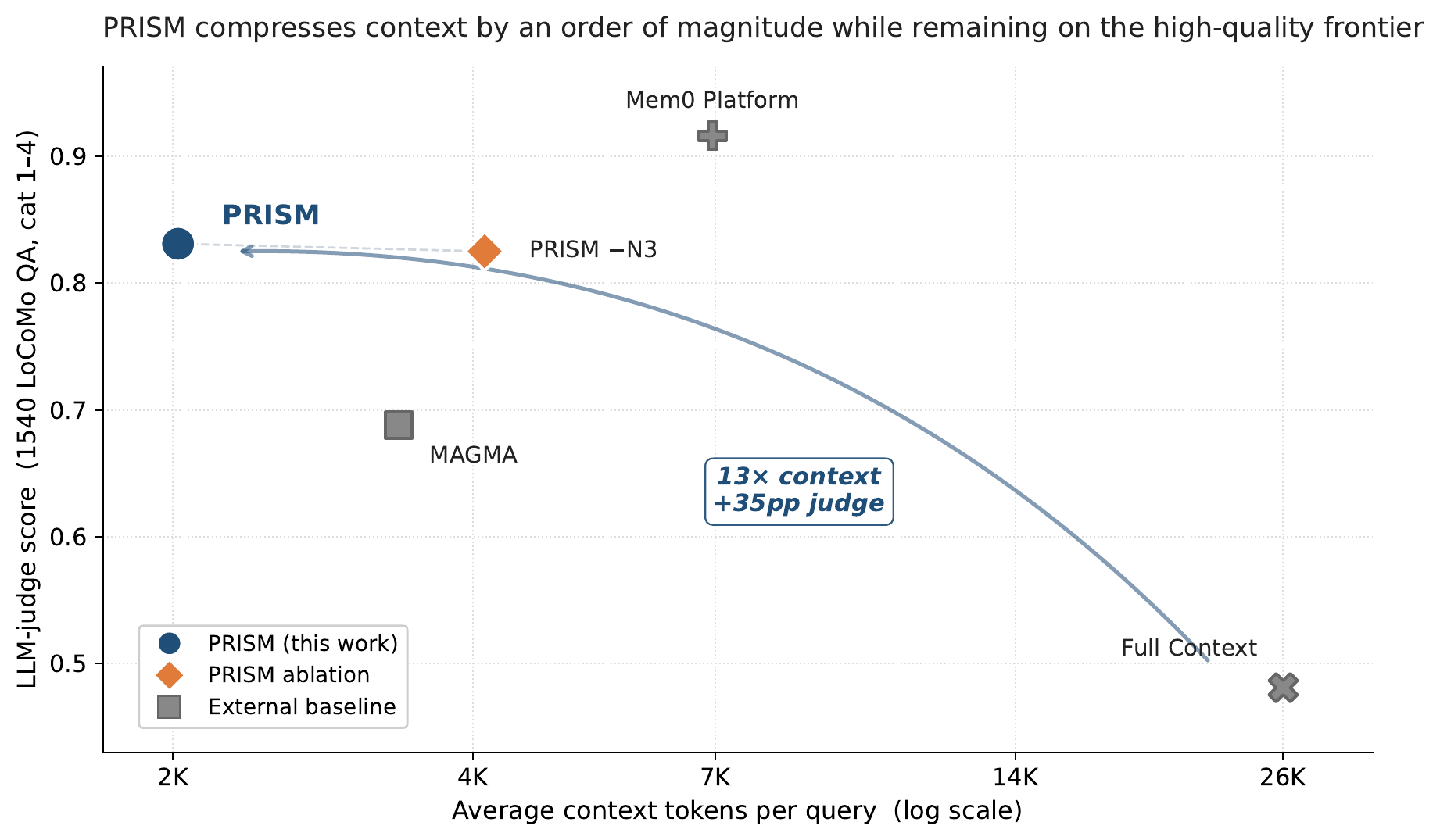
The context-efficiency frontier
Compared with full-context replay, PRISM achieves a 13× context reduction with a +35 pp judge gain — the two improvements are aligned, not traded off. Evidence Compression (N3) is the structural reason PRISM sits at the corner of the frontier rather than along its slope.
Accuracy–context trade-off on LoCoMo. Each point is one system; x-axis is average retrieved context tokens per query (log scale), y-axis is LLM-judge score. PRISM sits in the upper-left corner: high judge at low context.
Ablations & Analysis
What actually drives the gain.
Each ablation changes one flag relative to PRISM, reusing the same ingest checkpoint. The analysis is deliberately honest about which components matter on this benchmark — and which are built for harder settings.
N3 is the dominant lever
Removing the LLM re-ranker drops Evidence Recall@5 by 6.8 pp and roughly doubles answer-side context (2,023 → 4,108 tokens). Evidence Compression is what sets the frontier corner.
N1/N2 target harder benchmarks
On LoCoMo, relation paths and edge costs are null — 73.4% of questions cite a single evidence entry and only ~3% need a two-hop bridge. They are built for lexically-mismatched multi-hop settings like MuSiQue or HotpotQA.
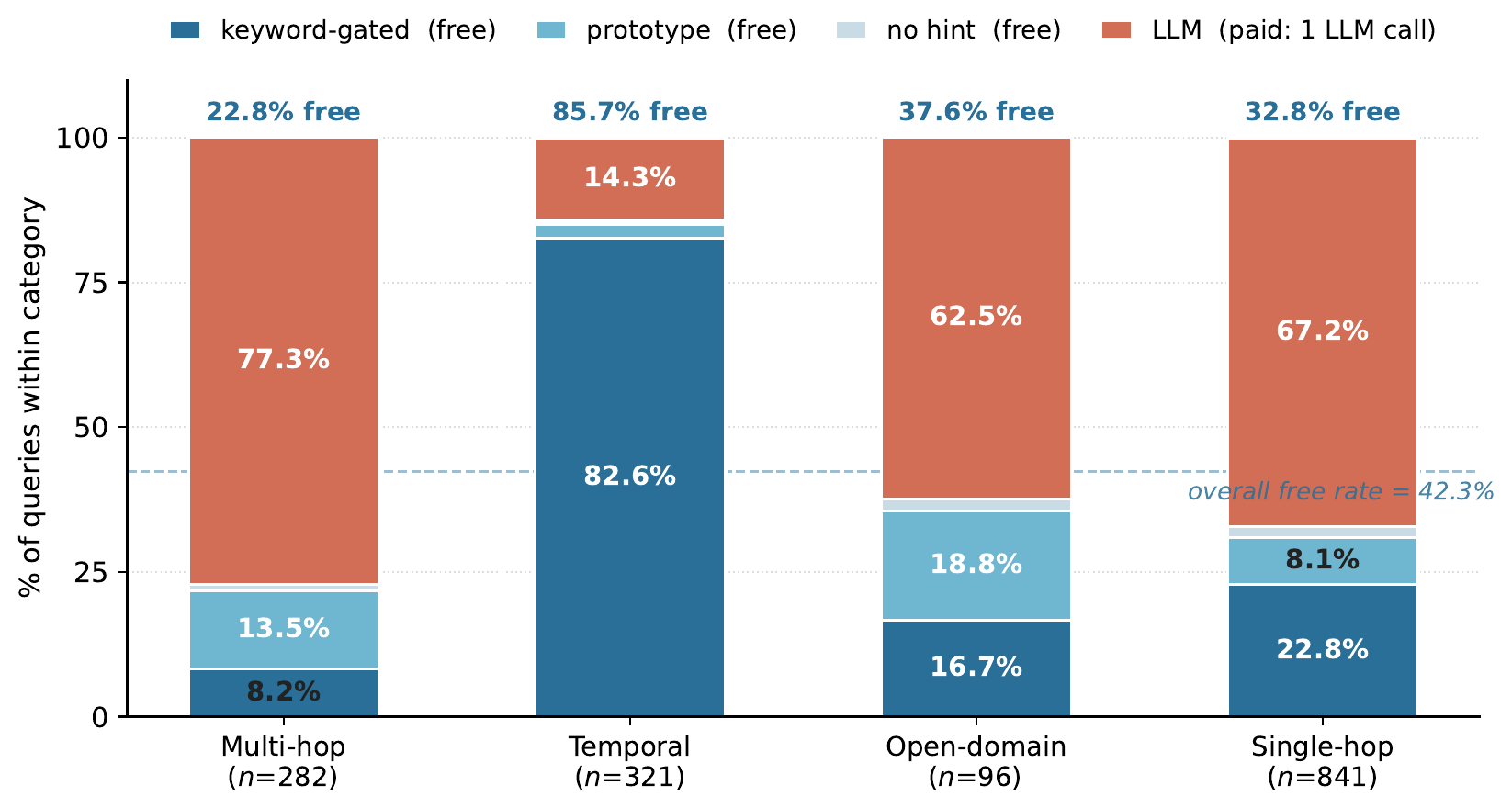
N4 cuts LLM calls at no accuracy cost
Adaptive Intent Routing handles 42.3% of queries through zero-LLM tiers without any measurable accuracy loss. The savings concentrate on temporal queries, 82.6% of which are resolved by keyword triggers alone.
Per-category routing distribution of N4. The keyword-gated, prototype, and no-hint paths incur zero LLM calls; only the LLM path costs one classifier-side call per query. Overall no-LLM rate: 42.3%.
Citation
Cite PRISM.
If you use PRISM in your research, please cite our paper:
@article{peng2026prism,
title = {PRISM: Pareto-Efficient Retrieval over Intent-Aware
Structured Memory for Long-Horizon Agents},
author = {Peng, Jingyi and Wan, Zhongwei and Liu, Weiting
and Sun, Qiuzhuang},
journal = {arXiv preprint arXiv:2605.12260},
year = {2026},
url = {https://arxiv.org/abs/2605.12260}
}